This wiki is locked. Future workgroup activity and specification development must take place at our new wiki. For more information, see this blog post about the new governance model and this post about changes to the website.
Asset Management Human Interaction Use Cases
1.0 Specification (future)
With many workproducts created across many delivery cycles from many teams using multiple tools and repositories, it is difficult for the business to preserve its investment in workproducts and leverage them as a strategic business asset and provide the trace-ability back to where and from whom the original workproducts came from. Having the right set of workproducts and relationships exposed in an asset repository for governance, search, and usage scenarios across teams and projects is central to the value proposition for asset management repositories. Roles In these scenarios there are two major roles, asset submitter and asset consumer. These roles overlap functional roles like developer, architect, tester and so forth. For example, this means a person in the role of developer can also take on the roles of asset submitter and asset consumer. These roles are briefly introduced.- Asset Submitter: performs asset preparation activities outlined in the publish scenario.
- Asset Consumer: performs asset searching and retrieval activities outlined in the search and retrieve scenarios.
Scenarios Overview - Asset Management System and Human interaction
Asset management plays an important role across the software delivery cycle. Here we will focus on the following scenarios:- Publish
- Submit asset information and files to repository for governance, review and approval, search and retrieval, measurement and reporting.
- Search
- Find and browse asset information and files, metrics, comments, related assets and other relevant information on the asset.
- Retrieve
- Pull a local copy of the asset information and possibly files for the asset.
Publish
Scenario: Developer Publishes Service Specification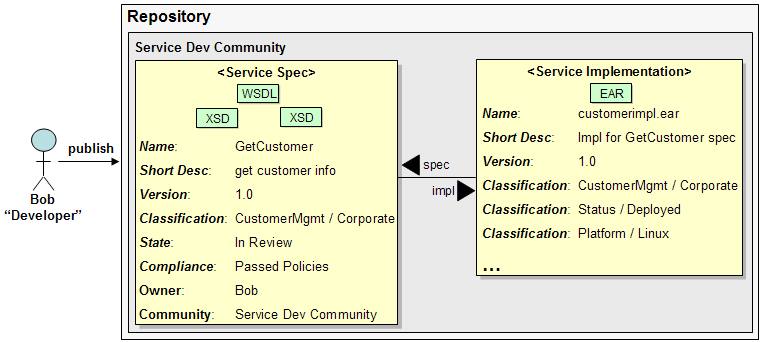 A developer has been creating a service specification (WSDL file and several XSD files), checking them into and out of a source control system. The developer has determined the service specification is mature enough to be governed and shared with other teams. The developer prepares to publish these workproducts as a service specification asset and fills in the relevant asset information (version, classification, ...) and selects the WSDL and XSD files (workproducts) and performs the publish. The developer examines the resulting message, indicating the service specification asset, with the WSDL and XSD files, has been successfully published to the asset repository. For our purposes here, we will assume that the Service Impl (customerimpl.ear) was submitted previously and Bob is not only submitting the service spec, but also creating the relationship to the service impl.
The published service specification asset may be part of an approval process and various groups collaborate, iterate, and vote on the specification moving it through its states until it is approved.
The published service specification may be updated (re-published) multiple times; updating metadata, artifacts, relationships and so on. The updated information may cause a state change. Each update (re-publish) is returned with a message on the result of the publish.
The published service specification may be examined by one or more policies either within the asset management system or another automated governance system. These policies examine the verity of the service specification artifacts, metadata, relationships, classification and so forth. The results of these examinations can be stored as metadata on the service specification.
Scenario: Architect Publishes Reference Architecture
An Architect has been developing a Reference Architecture that has reached a state where they are ready to share the Architecture with the development teams. They have been doing all of their work in a modeling environment, such as Rational Software Architect. The Architect selects that they are ready to publish the Reference Architecture to the asset repository. The modeling tool provides a way to select what items should be packaged together to form the asset. The Architect selects one or morel models and/or projects of other types that document the Reference Architecture and the points of variability. The Architect the provides necessary metadata, such as:
A developer has been creating a service specification (WSDL file and several XSD files), checking them into and out of a source control system. The developer has determined the service specification is mature enough to be governed and shared with other teams. The developer prepares to publish these workproducts as a service specification asset and fills in the relevant asset information (version, classification, ...) and selects the WSDL and XSD files (workproducts) and performs the publish. The developer examines the resulting message, indicating the service specification asset, with the WSDL and XSD files, has been successfully published to the asset repository. For our purposes here, we will assume that the Service Impl (customerimpl.ear) was submitted previously and Bob is not only submitting the service spec, but also creating the relationship to the service impl.
The published service specification asset may be part of an approval process and various groups collaborate, iterate, and vote on the specification moving it through its states until it is approved.
The published service specification may be updated (re-published) multiple times; updating metadata, artifacts, relationships and so on. The updated information may cause a state change. Each update (re-publish) is returned with a message on the result of the publish.
The published service specification may be examined by one or more policies either within the asset management system or another automated governance system. These policies examine the verity of the service specification artifacts, metadata, relationships, classification and so forth. The results of these examinations can be stored as metadata on the service specification.
Scenario: Architect Publishes Reference Architecture
An Architect has been developing a Reference Architecture that has reached a state where they are ready to share the Architecture with the development teams. They have been doing all of their work in a modeling environment, such as Rational Software Architect. The Architect selects that they are ready to publish the Reference Architecture to the asset repository. The modeling tool provides a way to select what items should be packaged together to form the asset. The Architect selects one or morel models and/or projects of other types that document the Reference Architecture and the points of variability. The Architect the provides necessary metadata, such as: - Name
- Description
- Depencencies on other assets
- Context for using Reference Architecture
- Whether the Architecture is recommended or required
- for approval purposes to be used by others
- to declare relationships to other assets, which may already be approved
- to submit the asset to a lifecycle so the appropriate teams may evaluate and refine it
- to declare the asset's type
- name
- version (asset version, not workproduct version)
- asset type (describing the asset's expected content, constraints, lifecycle, state, relationships, categorization)
- description
- relationships/dependencies to other assets
- workproducts, contained directly, or referenced
- published location (server, community)
- date submitted
- submitter's roles and permissions
- permissions of potential users
- asset's unique identifier
Search
Scenario: Developer Searches for Service Specification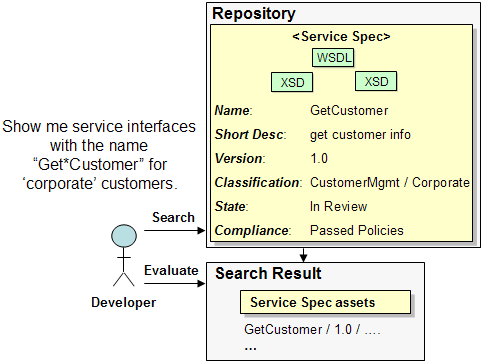 A developer is building an application and needs to find an existing, approved service to use. To find the service the developer provides service information to search such as the service name, description, classification, relationships, attributes, artifact information, and other metadata (such as preferred sort). The developer also provides keywords, wildcards and variant keyword phrases. The developer also indicates the scope of the search, indicating what level of the metadata to search, such as the service's artifact information - such as the WSDL operation name.
The developer issues the search, viewing the service information on the result list such as service name, version description, asset type, ratings, attributes, artifacts, and related assets. The result list includes information on each asset about its position and relevance in the result list. The developer sorts the result list by the approved date.
The developer pages through the result list examining the service's artifact names (such as the WSDL artifact in the service, and the operation name that was found), the service description, and so forth. After reviewing the result list, the developer shares it with another developer, who examines the service information on the result list.
The search could be performed by a human or by a system.
Scenario: Developer Searches for Service Specification and Implementation
A developer is building an application and needs to find an existing, approved service to use. To find the service the developer provides service information to search such as the service name, description, classification, relationships, attributes, artifact information, and other metadata (such as preferred sort). The developer also provides keywords, wildcards and variant keyword phrases. The developer also indicates the scope of the search, indicating what level of the metadata to search, such as the service's artifact information - such as the WSDL operation name.
The developer issues the search, viewing the service information on the result list such as service name, version description, asset type, ratings, attributes, artifacts, and related assets. The result list includes information on each asset about its position and relevance in the result list. The developer sorts the result list by the approved date.
The developer pages through the result list examining the service's artifact names (such as the WSDL artifact in the service, and the operation name that was found), the service description, and so forth. After reviewing the result list, the developer shares it with another developer, who examines the service information on the result list.
The search could be performed by a human or by a system.
Scenario: Developer Searches for Service Specification and Implementation
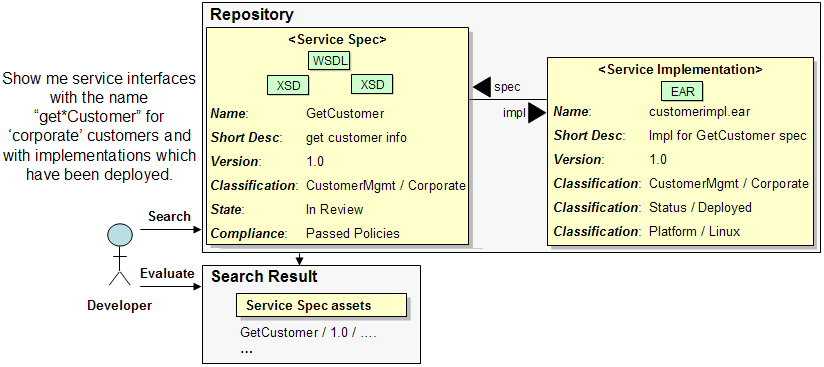 In this scenario a developer searches using asset relationships in addition to the other service information. In this case the developer is looking for service specifications which have associated implementations which have been deployed.
Scenario: Architect Searches for Reference Architecture
The asset information and workproducts provided in the Publish scenario provide the basis for searching and browsing.
In the search scenario the Asset Consumer uses asset information to search for the asset. They are developing a new system and need to find a Reference Architecture that matches their type of system. They are in a modeling environment, such as Rational Software Architect, and select that they would like to find a Reference Architecture. The modeling tool collects the search parameters such as the context of the desired application, keywords, etc.
The set of searchable assets are constrained by the access rights of the asset consumer; which means that another asset consumer with different access rights while using the same search parameters may have a different result set.
The search returns the search result for the provided search parameters and user access rights. The Asset Consumer browses the asset information on the search result (i.e., browses the asset meta data). The service artifacts are NOT downloaded during this scenario; but are downloaded as part of the Retrieve scenario.
Background for Search Scenario
The asset information and workproducts provided in the Publish scenario provide the basis for searching and browsing.
In the search scenario the Asset Consumer uses asset information to search for the asset. The search allows the asset consumer to perform structured searching using classification, asset type, and other structured elements. The search also allows unstructured searching using keywords, wildcards, and variant phrase searching. Any given search may have any given number of structured and unstructured searching parameters.
The set of searchable assets are constrained by the access rights of the asset consumer; which means that another asset consumer with different access rights while using the same search parameters may have a different result set.
The search returns the search result for the provided search parameters and user access rights. The Developer browses the asset information on the search result (i.e., browses the asset meta data). The service artifacts are NOT downloaded during this scenario; but are downloaded as part of the Retrieve scenario.
In this scenario a developer searches using asset relationships in addition to the other service information. In this case the developer is looking for service specifications which have associated implementations which have been deployed.
Scenario: Architect Searches for Reference Architecture
The asset information and workproducts provided in the Publish scenario provide the basis for searching and browsing.
In the search scenario the Asset Consumer uses asset information to search for the asset. They are developing a new system and need to find a Reference Architecture that matches their type of system. They are in a modeling environment, such as Rational Software Architect, and select that they would like to find a Reference Architecture. The modeling tool collects the search parameters such as the context of the desired application, keywords, etc.
The set of searchable assets are constrained by the access rights of the asset consumer; which means that another asset consumer with different access rights while using the same search parameters may have a different result set.
The search returns the search result for the provided search parameters and user access rights. The Asset Consumer browses the asset information on the search result (i.e., browses the asset meta data). The service artifacts are NOT downloaded during this scenario; but are downloaded as part of the Retrieve scenario.
Background for Search Scenario
The asset information and workproducts provided in the Publish scenario provide the basis for searching and browsing.
In the search scenario the Asset Consumer uses asset information to search for the asset. The search allows the asset consumer to perform structured searching using classification, asset type, and other structured elements. The search also allows unstructured searching using keywords, wildcards, and variant phrase searching. Any given search may have any given number of structured and unstructured searching parameters.
The set of searchable assets are constrained by the access rights of the asset consumer; which means that another asset consumer with different access rights while using the same search parameters may have a different result set.
The search returns the search result for the provided search parameters and user access rights. The Developer browses the asset information on the search result (i.e., browses the asset meta data). The service artifacts are NOT downloaded during this scenario; but are downloaded as part of the Retrieve scenario.
Retrieve
Scenario: Developer Retrieves Service Assets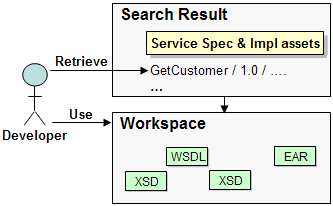 A developer is building an application and has found a service specification to use. The service specification may have been found through the Search use case described above, or a reference to the service specification may have been given to the developer by another developer or as part of a review process.
The developer examines the service specification more closely, browsing its information and artifact lists. When the developer is satisfied the developer downloads the service specification's artifacts, which are retrieved to a local workspace.
If the service specification has dependencies to other assets, the developer is given an option to retrieve those assets, if selected, the related assets artifacts are downloaded as well. The service specification and related assets may be retrieved as part of an asset review process.
Scenario: Architect Retreives Reference Architecture Assets
In this scenario, the Asset Consumer is developing a new system and has found a Reference Architecture that they would like to retrieve into their modeling tool and start developing a new system, using the Reference Architecture as a starting point. They select the desired Reference Architecture and the modeling environment retrieves the Reference Architecture and makes a new instance of it. The Asset Consumer then uses the modeling tool to iterate through the variability points and select the correct options for the new system. The modeling environment creates a new asset in the repository for this instantiation of the Reference Architecture. It captures the variability and creates traceability to the Reference Architecture. The Asset Consumer the proceeds to develop the system.
Background for Retrieve Scenario
Upon browsing the asset information, the asset's artifacts provided in the Publish scenario are then browsed and eventually retrieved into a target location.
The set of retrievable assets are constrained by the access rights of the asset consumer; which means that another asset consumer with different access rights may be not be able to retrieve the asset.
The kind of information retrieved for assets includes the asset's information (or metadata) including, but not limited to, items such as:
A developer is building an application and has found a service specification to use. The service specification may have been found through the Search use case described above, or a reference to the service specification may have been given to the developer by another developer or as part of a review process.
The developer examines the service specification more closely, browsing its information and artifact lists. When the developer is satisfied the developer downloads the service specification's artifacts, which are retrieved to a local workspace.
If the service specification has dependencies to other assets, the developer is given an option to retrieve those assets, if selected, the related assets artifacts are downloaded as well. The service specification and related assets may be retrieved as part of an asset review process.
Scenario: Architect Retreives Reference Architecture Assets
In this scenario, the Asset Consumer is developing a new system and has found a Reference Architecture that they would like to retrieve into their modeling tool and start developing a new system, using the Reference Architecture as a starting point. They select the desired Reference Architecture and the modeling environment retrieves the Reference Architecture and makes a new instance of it. The Asset Consumer then uses the modeling tool to iterate through the variability points and select the correct options for the new system. The modeling environment creates a new asset in the repository for this instantiation of the Reference Architecture. It captures the variability and creates traceability to the Reference Architecture. The Asset Consumer the proceeds to develop the system.
Background for Retrieve Scenario
Upon browsing the asset information, the asset's artifacts provided in the Publish scenario are then browsed and eventually retrieved into a target location.
The set of retrievable assets are constrained by the access rights of the asset consumer; which means that another asset consumer with different access rights may be not be able to retrieve the asset.
The kind of information retrieved for assets includes the asset's information (or metadata) including, but not limited to, items such as: - name
- version (asset version, not workproduct version)
- asset type (describing the asset's expected content, constraints, lifecycle, state, relationships, categorization)
- description
- relationships/dependencies to other assets
- workproducts, contained directly, or referenced
- published location (server, community)
- date submitted
- submitter's roles and permissions
- permissions of potential users
- asset's unique identifier
Other
The Powerpoint file with the images for these scenarios can be retrieved from here.Work Group Scenario Brainstorming
AssetMgScenariosCiti? AssetMgScenariosBlackDuck? AssetMgScenariosEmphasys AssetMgScenariosIRam AssetMgScenariosWebLayers AssetMgScenariosRAMTeamEdit | Attach | Print version | History: r1 | Backlinks | Raw View | Raw edit | More topic actions
Topic revision: r1 - 08 Jan 2010 - 20:39:18 - KevinBauer
|
|
Contributions are governed by our Terms of Use
Ideas, requests, problems regarding this site? Send feedback